Post by Olga Golosova on May 5th, 2017 at 5:22pm
I'm not sure I fully understand what you would like to achieve, however here is a couple of ideas that may help you:
1) If you remove one or two columns in the alignment before converting it to the amino acid one you'll shift the reading frame.
2) To get all three reading frames per each sequence you may use the Workflow Designer. Screenshot of the workflow and the result is attached. If you need more details about this solution please write.
translate_sequences_workflow.png
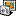 translate_sequences_workflow.png (154 KB | 445
)
translate_sequences_workflow.png (154 KB | 445
)
1) If you remove one or two columns in the alignment before converting it to the amino acid one you'll shift the reading frame.
2) To get all three reading frames per each sequence you may use the Workflow Designer. Screenshot of the workflow and the result is attached. If you need more details about this solution please write.
translate_sequences_workflow.png
translate_sequences_workflow.png (154 KB | 445
)



